

Why the Prototype-to-Production Gap Exists

AI development tools are optimized for speed and functional correctness. They produce clean interfaces, implement recognizable design patterns, and translate business logic into working code with remarkable efficiency. What they do not produce — by design — is the invisible infrastructure that enterprise software requires to survive contact with the real world.
This is not a flaw in the tools. It is a structural characteristic of how they operate. They solve for getting to working quickly, not for staying reliable over time.
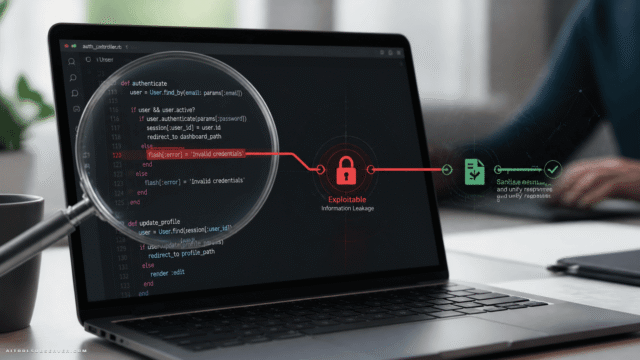
The data confirms this. Veracode’s 2025 GenAI Code Security Report, which tested output from over 100 large language models across four programming languages, found that AI-generated code introduced security vulnerabilities in 45% of cases. More advanced models did not produce meaningfully more secure code than smaller ones. The gap is not closed by better AI — it is closed by human engineering judgment applied systematically.
The good news: you do not start from zero. The prototype has already completed the most expensive phase of traditional software development — discovery. The business logic is defined, the user experience is validated, and the core functionality works. What remains is hardening, not rebuilding.
Phase 1: Assessment — Know What You Have

Before any remediation begins, you need an honest inventory of the existing codebase. This phase determines what carries forward, what needs fixing, and what needs to be rebuilt entirely.
1.1 Codebase Review
- Identify all dependencies and third-party libraries; check for known vulnerabilities using a software composition analysis (SCA) tool.
- Review the code for common AI-generation patterns that introduce risk: hardcoded credentials, missing input validation, overly permissive error handling.
- Document the application’s data flows — what data enters the system, where it is stored, and how it moves between components.
1.2 Architecture Evaluation
- Map the current architecture against your organization’s production standards. Does it assume a single user or a single environment?
- Identify single points of failure: database connections without pooling, synchronous calls that block under load, stateful components that cannot scale horizontally.
- Assess whether the application was built for the cloud environment it will actually run in — AWS, Azure, or on-premises infrastructure each impose different constraints.
1.3 Integration Landscape
- List every external system the application touches: APIs, databases, identity providers, third-party services.
- Verify that integration credentials are managed securely, not embedded in source code or configuration files committed to version control.
- Confirm that the application respects rate limits, handles API failures gracefully, and does not create circular dependencies with upstream systems.
Assessment output: A prioritized remediation list, categorized by severity — critical blockers, significant risks, and quality improvements. This list drives Phase 2.
Phase 2: Remediation and Hardening — Close the Gaps
This is the core engineering work. It is methodical, not creative. Each item below represents a category of risk that AI-generated prototypes consistently leave open.
2.1 Security Hardening
Security is non-negotiable. Address these items before any production data touches the application.
Authentication and authorization
- Replace any prototype-grade authentication (hardcoded users, simple password checks) with your organization’s identity provider — SAML, OAuth 2.0, or OpenID Connect.
- Implement role-based access control (RBAC) with the principle of least privilege. Every user and service account should have exactly the permissions required, nothing more.
- Enforce multi-factor authentication for all administrative access.
Input validation and injection prevention
- Audit every point where user input enters the system. Validate type, length, format, and range server-side — never rely on client-side validation alone.
- Use parameterized queries or prepared statements for all database interactions. AI-generated code frequently constructs SQL queries through string concatenation, which is a direct injection risk.
- Sanitize output to prevent cross-site scripting (XSS) in any web-facing component.
Secrets management
- Remove all hardcoded credentials, API keys, and connection strings from the codebase immediately.
- Migrate secrets to a dedicated secrets management service: AWS Secrets Manager, Azure Key Vault, or HashiCorp Vault depending on your environment.
- Rotate any credentials that were previously exposed in source code or configuration files.
Dependency management
- Pin dependency versions and establish a process for monitoring and applying security patches.
- Remove unused dependencies — they expand the attack surface without providing value.
- Integrate SCA scanning into your build pipeline so new vulnerabilities are flagged automatically.
2.2 Scalability and Architecture
A prototype built for one user in one environment will behave unpredictably under production load. Address the structural issues before they become incidents.
Stateless design
- Refactor components that store session state locally so that state is managed externally — in a cache layer like Redis or in the database. This enables horizontal scaling.
- Ensure that multiple instances of the application can run simultaneously without conflicting with each other.
Database optimization
- Review query patterns and add indexes where missing. AI-generated code often produces functionally correct queries that perform poorly at scale.
- Implement connection pooling. Direct database connections without pooling collapse under concurrent load.
- Separate read and write workloads where the data model supports it.
Asynchronous processing
- Identify operations that do not need to complete synchronously — report generation, email sending, data exports, third-party API calls with variable latency.
- Move these operations to a message queue or background job system. This keeps the application responsive under load and isolates failures.
Caching strategy
- Define what data can be cached and for how long. Implement caching at the appropriate layer — application, API, or database — based on access patterns.
- Establish cache invalidation rules. Stale cache data in a production system causes subtle, difficult-to-diagnose errors.
2.3 Testing and Quality Assurance
AI-generated prototypes are typically tested manually, if at all. Production software requires automated verification at multiple levels.
Unit and integration testing
- Write unit tests for all business logic. Aim for meaningful coverage of critical paths, not an arbitrary percentage metric.
- Implement integration tests that verify the application behaves correctly when connected to real dependencies — databases, APIs, identity providers.
Load and performance testing
- Define your expected peak load: concurrent users, transactions per second, data volume.
- Run load tests against a production-equivalent environment before go-live. Identify the breaking point and ensure it is well above your expected peak.
Security testing
- Run a static application security testing (SAST) scan against the codebase and remediate findings by severity.
- Conduct dynamic application security testing (DAST) against a running instance of the application.
- For applications handling sensitive data, commission a penetration test from an independent party.
2.4 DevOps and Deployment Pipeline
Manual deployment is not a production practice. Establish automation before the first production release.
CI/CD pipeline
- Configure a continuous integration pipeline that runs automated tests on every code change. No code merges without passing tests.
- Implement a continuous delivery pipeline that automates deployment to staging and production environments with consistent, repeatable processes.
- Include security scanning (SAST, dependency checks) as mandatory pipeline gates.
Environment parity
- Ensure that development, staging, and production environments are configured identically, differing only in scale and data. Environment-specific bugs are among the most expensive to diagnose.
- Use infrastructure-as-code (Terraform, Bicep, CloudFormation) to define and version your infrastructure alongside your application code.
Rollback capability
- Every production deployment must have a tested rollback procedure. Define it before you need it.
- Implement blue-green or canary deployment strategies for high-risk releases to limit blast radius.
Phase 3: Compliance, Governance, and Production Readiness
Technical hardening is necessary but not sufficient. Enterprise production requires organizational controls alongside engineering ones.
3.1 Compliance Requirements
- Identify the regulatory frameworks that apply to your application: GDPR, HIPAA, SOC 2, PCI DSS, or sector-specific requirements.
- Map data flows against compliance requirements. Confirm that personal data is collected with appropriate consent, stored with appropriate controls, and deleted according to retention policies.
- Document the application’s data processing activities. This documentation is required for compliance audits and is far easier to produce before production than after.
3.2 Observability and Incident Response
You cannot manage what you cannot see. Production applications require visibility into their behavior.
- Implement structured logging that captures meaningful events — authentication attempts, data access, errors, performance metrics — without logging sensitive data.
- Configure monitoring and alerting for key health indicators: error rates, response times, resource utilization, failed authentication attempts.
- Define an on-call process and incident response runbook before go-live. Who is notified when the application fails at 2 a.m.? What are the escalation steps?
3.3 Governance Framework
This is the organizational layer that makes AI-assisted development sustainable at scale.
Production readiness review
- Establish a lightweight but mandatory review process for any AI-generated application before it reaches production. The checklist in this guide is a starting point.
- Assign clear ownership: who is responsible for the application’s security posture, compliance status, and operational reliability?
Change management
- All changes to production applications must go through version control and the CI/CD pipeline. No manual edits to production systems.
- Maintain a change log. When something breaks, you need to know what changed and when.
Vendor and dependency governance
- Document all third-party services and APIs the application depends on. Assess each for reliability, security posture, and contractual terms.
- Establish a process for evaluating and approving new dependencies before they are introduced.
3.4 Documentation
Documentation is not optional for enterprise software. It is a risk management tool.
- Produce a system architecture document that describes how the application works, what it connects to, and how it is deployed.
- Write an operations runbook covering routine maintenance tasks, common failure scenarios, and their resolutions.
- Document the data model and any business logic that is not self-evident from the code.
The Production Readiness Checklist at a Glance
Use this summary as a go/no-go gate before any AI-generated application enters production.
Security
- [ ] Authentication integrated with organizational identity provider
- [ ] Role-based access control implemented
- [ ] All secrets removed from codebase and managed in a secrets vault
- [ ] Input validation and injection prevention verified
- [ ] Dependencies scanned and vulnerabilities remediated
- [ ] SAST and DAST scans completed
Scalability
- [ ] Stateless architecture verified or implemented
- [ ] Database queries optimized and connection pooling configured
- [ ] Asynchronous processing implemented for long-running operations
- [ ] Load testing completed against production-equivalent environment
DevOps
- [ ] CI/CD pipeline configured with automated testing gates
- [ ] Infrastructure defined as code
- [ ] Rollback procedure documented and tested
- [ ] Environment parity confirmed across development, staging, and production
Compliance and Governance
- [ ] Applicable regulatory requirements identified and mapped
- [ ] Data retention and deletion policies implemented
- [ ] Structured logging and monitoring configured
- [ ] Incident response runbook documented
- [ ] Application ownership assigned
- [ ] Architecture and operations documentation complete
A Note on Scope and Prioritization
Not every item on this checklist carries equal weight for every application. An internal reporting tool used by ten analysts has a different risk profile than a customer-facing portal processing financial transactions. Apply judgment proportional to the application’s exposure, data sensitivity, and business criticality.
What does not change with scope is the sequence. Security hardening comes before scalability work. Observability is configured before go-live, not after the first incident. Governance documentation is produced during the process, not reconstructed from memory six months later.
The organizations that build a repeatable version of this process — adapted to their environment and risk tolerance — will move AI-generated applications into production faster, more safely, and with less organizational friction than those that evaluate each prototype as a one-off problem.
The Structural Advantage
AI-assisted development has permanently compressed the discovery phase of custom software delivery. The prototype your team built in a weekend represents weeks of traditional requirements gathering, design work, and initial development. That compression is real business value — but only if the organization has a clear path from prototype to production.
The checklist above is that path. It is not a reason to slow down. It is the engineering discipline that makes the speed sustainable.








Comments (0) No comments yet
Want to join this discussion? Login or Register.
No comments yet. Be the first to share your thoughts!